
PDFlib TET PDF IFilter
PDF 문서에서 텍스트와 메타 데이터를 추출합니다.
PDFlib사에서 공개
2003년 부터 ComponentSource에서 판매중

PDFlib TET PDF IFilter extracts text and metadata from PDF documents and makes it available to search and retrieval software on Windows. This allows PDF documents to be searched on the local desktop, a corporate server, or the Web.

이미지 1/12
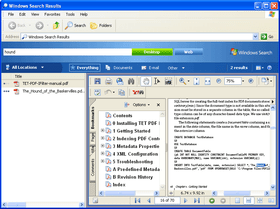
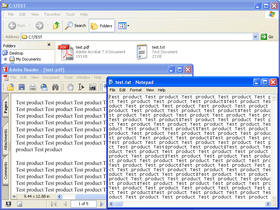
TET PDF IFilter extracts text and metadata from PDF documents and makes it available to search and retrieval software on Windows. This allows PDF documents to be searched on the local desktop, a corporate server, or the Web. TET PDF IFilter is based on the patented PDFlib Text Extraction Toolkit (TET), which is a developer product for reliably extracting text from PDF documents.
TET PDF IFilter is a robust implementation of Microsoft’s IFilter indexing interface. It works with all search and...

PDFlib 사 제품 라이선스 담당자와 라이브 채팅



전화 : 00798 14 800 6332
팩스 : +1 770 250 6199



