


Fournisseur officiel
Comme nous somme les distributeurs officiels et autorisés, nous vous fournissons des licences légitimes directement à partir de 200+ éditeurs de logiciels.
Voyez toutes nos marques.
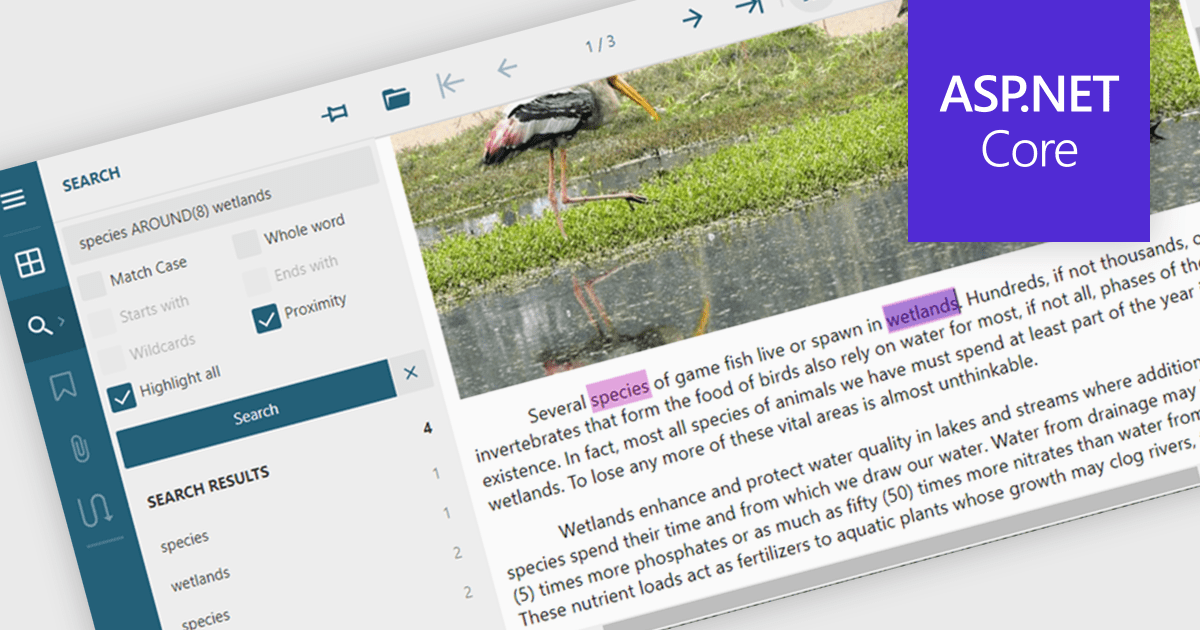
Continuer de lire en anglais:
Text searching in a PDF component refers to the ability to programmatically locate and extract text within a PDF document based on specific search criteria. This functionality typically supports case sensitivity, whole word matching, and regular expressions, enabling precise querying across pages or document sections. For developers, it facilitates building features such as keyword highlighting, document indexing, content validation, and automated redaction workflows. By integrating text search, applications can efficiently interact with PDF content without manual review, saving time and improving data accessibility and accuracy across business and document automation systems.
Several ASP.NET Core PDF components allow you to search for text within a PDF file, including:
For an in-depth analysis of features and price, visit our comparison of ASP.NET Core PDF components.










Tél : (888) 850 9911
Fax : +1 770 250 6199




