












공식 공급 업체
200 이상의 소프트웨어 개발처와 판매 계약을 맺은 공인 디스트리뷰터로서 합법적인 라이선스를 제공합니다.
모든 브랜드 보기.
영어로 계속 읽기:
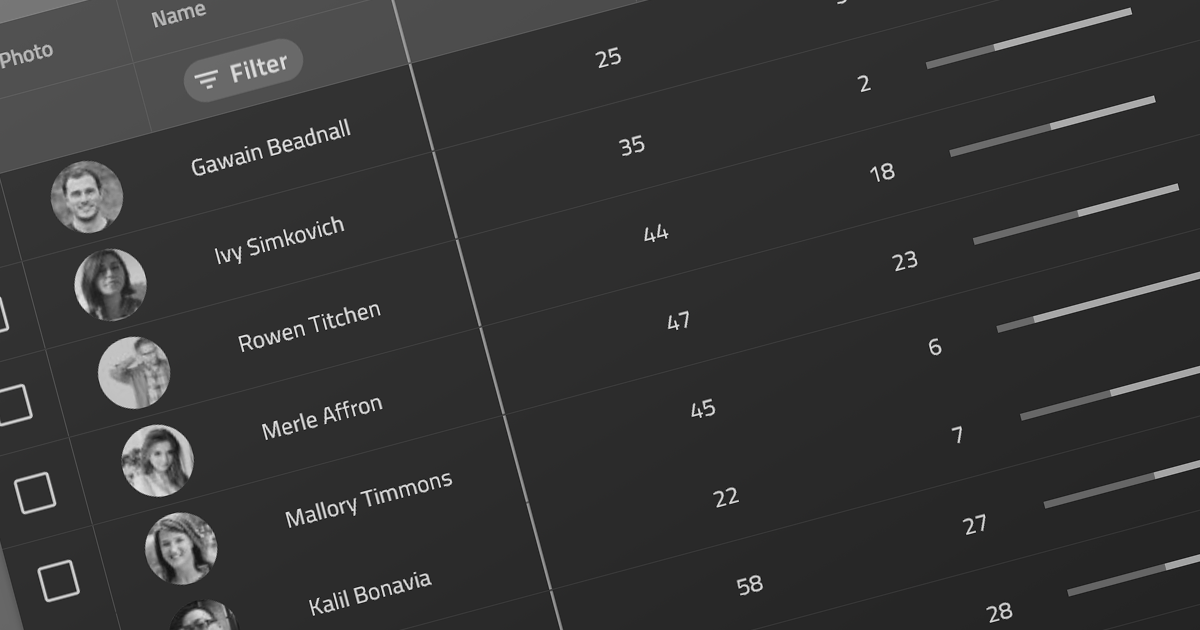
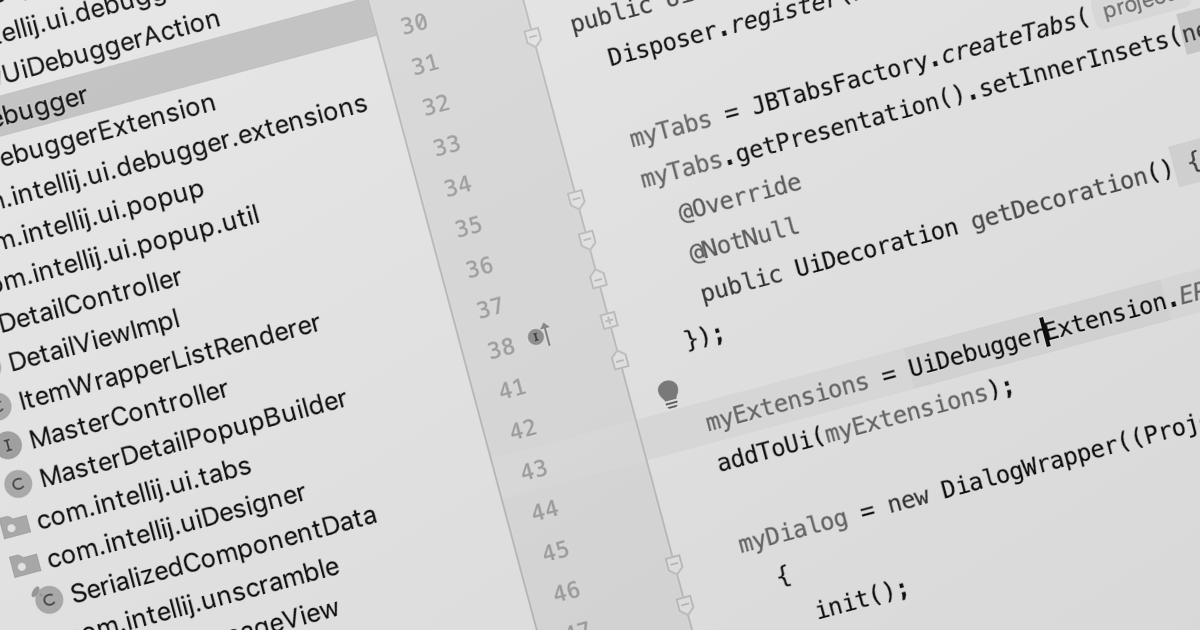
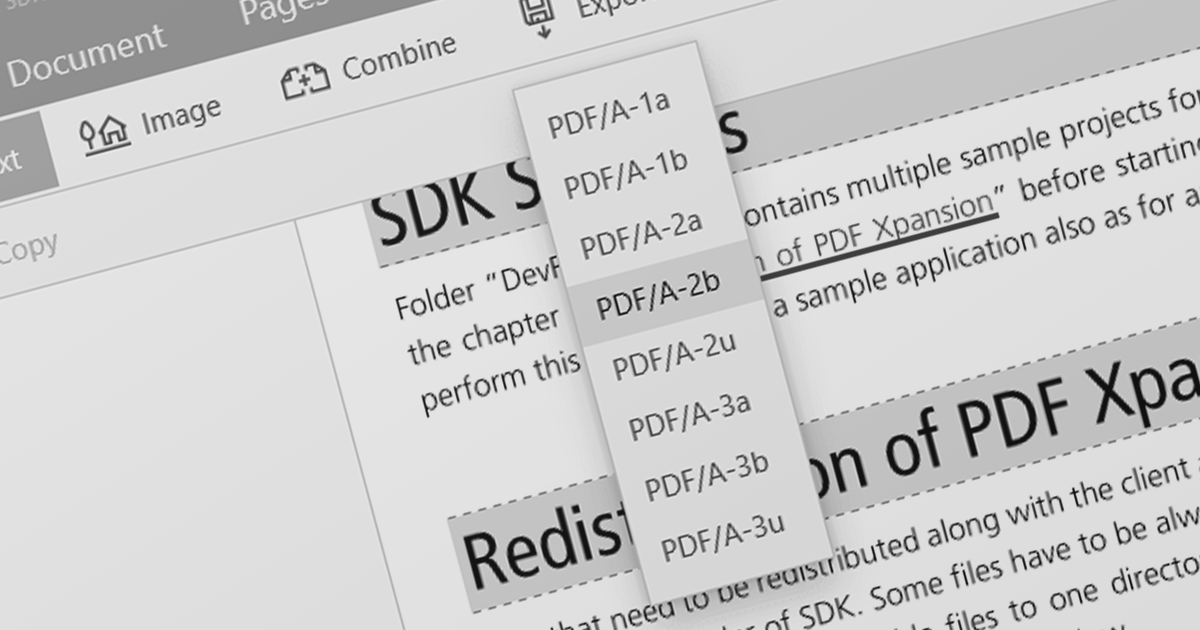
PDF data extraction is the process of programmatically extracting textual and visual information from PDF documents. It enables developers to parse files, extract text, images, and other elements, facilitating tasks like document indexing, and text mining.
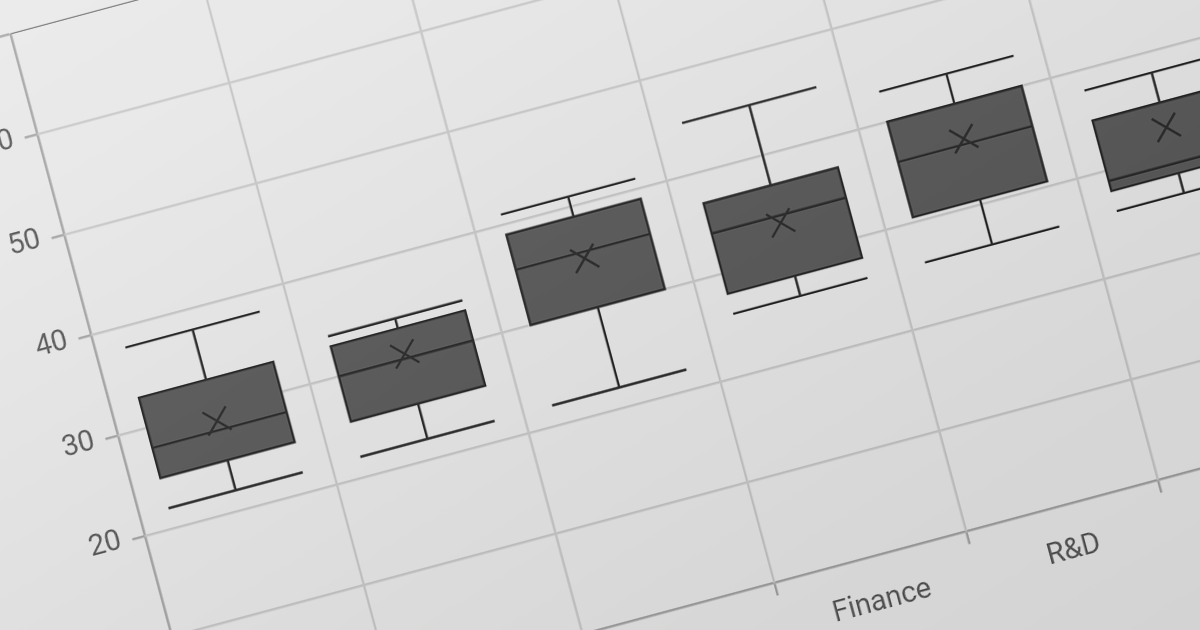
Several .NET PDF components provide content extraction capabilities, including:
For an in-depth analysis of features and price, visit our comparison of .NET PDF components.
전화 : 00798 14 800 6332
팩스 : +1 770 250 6199




