












공식 공급 업체
200 이상의 소프트웨어 개발처와 판매 계약을 맺은 공인 디스트리뷰터로서 합법적인 라이선스를 제공합니다.
모든 브랜드 보기.
영어로 계속 읽기:
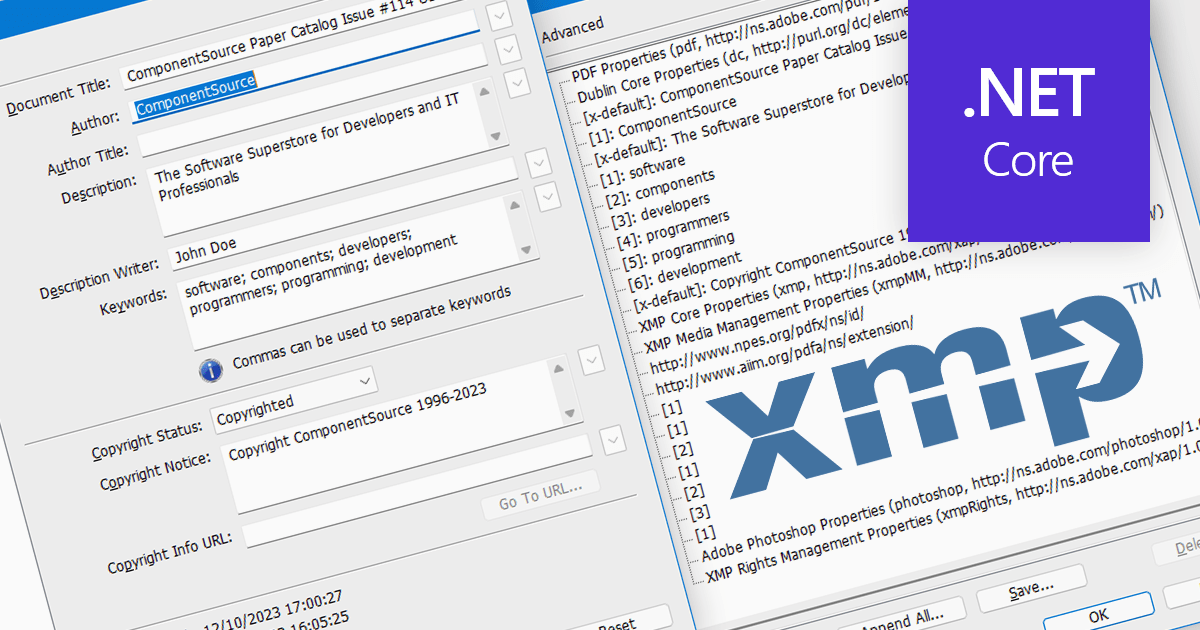
XMP, or Extensible Metadata Platform, acts like a digital label embedded within PDFs, carrying information beyond the document itself. It holds details like author names, creation dates, keywords, and even revision history. Programmatically extracting this XMP data unlocks a treasure trove of possibilities. Imagine automatically organizing PDFs based on author or keyword, extracting copyright information for legal purposes, or even tracing the evolution of a document through its XMP timestamps. This power makes XMP extraction invaluable for researchers, librarians, and anyone who wants to squeeze the most out of their PDF collection.
Several .NET Core PDF components support the extraction of XMP metadata including:
For an in-depth analysis of features and price, visit our .NET Core PDF Components comparison.
전화 : 00798 14 800 6332
팩스 : +1 770 250 6199




