
PDF4NET
PDF enable your .NET applications.
Published by PDF4DEV Solutions
Distributed by ComponentSource since 2004
Prices from: US$ 685.02 Version: 16.2.2 NEW Updated: May 1, 2026 ![]()
![]()
![]()
![]()
![]() (6)
(6)
PDF enable your .NET applications.
Published by PDF4DEV Solutions
Distributed by ComponentSource since 2004
Prices from: US$ 685.02 Version: 16.2.2 NEW Updated: May 1, 2026 ![]()
![]()
![]()
![]()
![]() (6)
(6)

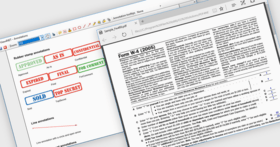
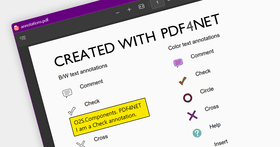
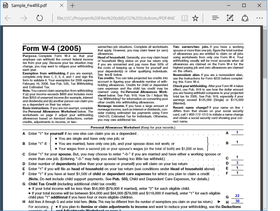
PDF4NET is a .NET library for generating and importing PDF documents on the fly from any .NET application. The library does not rely on any Adobe products for creating and importing PDF files. It hides the complex structure of PDF files behind a simple object model that allows creation of complex PDF files or import of existing PDF files with a few lines of code.

The PDF4NET library can use either a grid based layout approach allowing precise positioning of content on document's pages or a flow based layout making the generation of complex documents a breeze. The final PDF file is compressed, making the library appropriate for web applications. The library can be used from WinForms, ASP.NET, WPF, UWP, .NET Core, Mac, iOS and Android applications without any restrictions,the source code being fully portable between platforms. The library is written...



PDF4NET is also available in:
Live Chat with our PDF4DEV Solutions licensing specialists now.



Very good product.
Tel: (888) 850 9911
Fax: +1 770 250 6199




