
PDFlib TET PDF IFilter
Extraiga texto y metadatos de documentos PDF.
Publicado por PDFlib
Distribuido por ComponentSource desde 2003
Ya no suministramos este producto.
Extraiga texto y metadatos de documentos PDF.
Publicado por PDFlib
Distribuido por ComponentSource desde 2003

Please note: PDFlib TET PDF IFilter was officially retired as of December 19th 2024. If you are interested in this product, consider PDFlib instead.
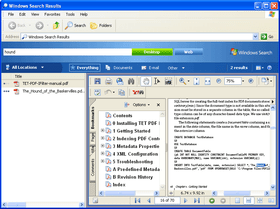
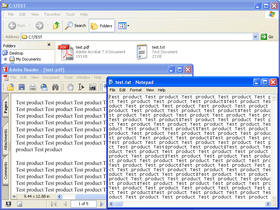
PDFlib TET PDF IFilter extracts text and metadata from PDF documents and makes it available to search and retrieval software on Windows. This allows PDF documents to be searched on the local desktop, a corporate server, or the Web.

Imagen 1 / 12
TET PDF IFilter extracts text and metadata from PDF documents and makes it available to search and retrieval software on Windows. This allows PDF documents to be searched on the local desktop, a corporate server, or the Web. TET PDF IFilter is based on the patented PDFlib Text Extraction Toolkit (TET), which is a developer product for reliably extracting text from PDF documents.
TET PDF IFilter is a robust implementation of Microsoft’s IFilter indexing interface. It works with all search and...

Chatee en vivo ahora mismo con nuestros especialistas en licencias de PDFlib.



Tel: (888) 850 9911
Fax: +1 770 250 6199




