












Proveedor oficial
Como distribuidores oficiales y autorizados, le suministramos licencias legítimas directamente de más de 200 editores de software.
Ver todas nuestras marcas.
Continuar leyendo en inglés:
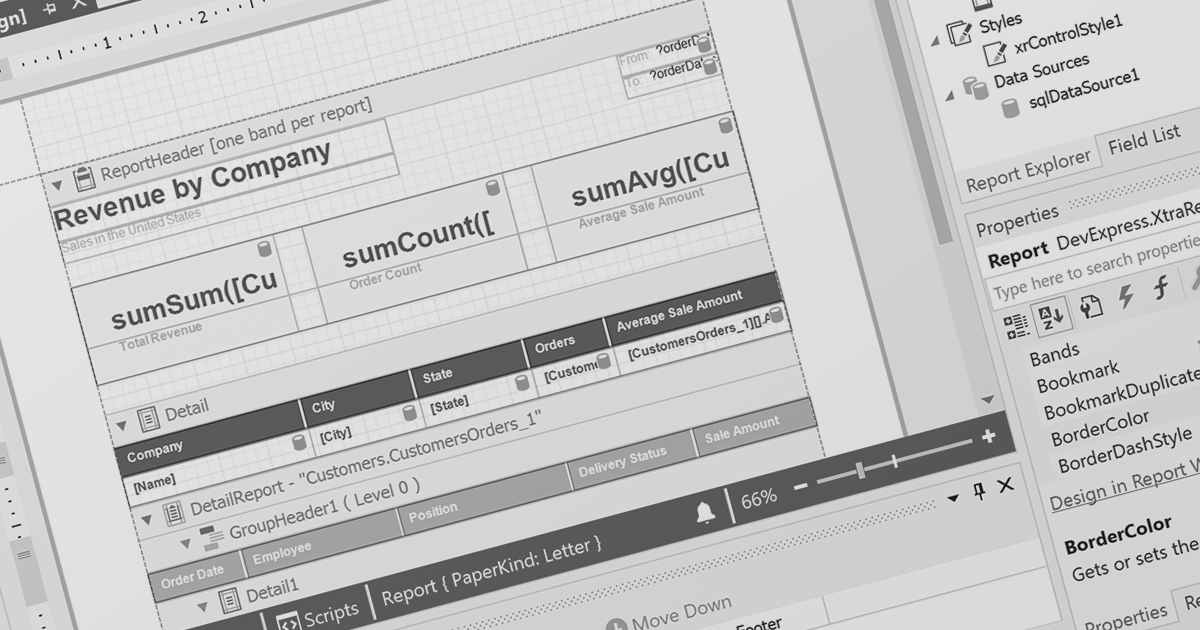
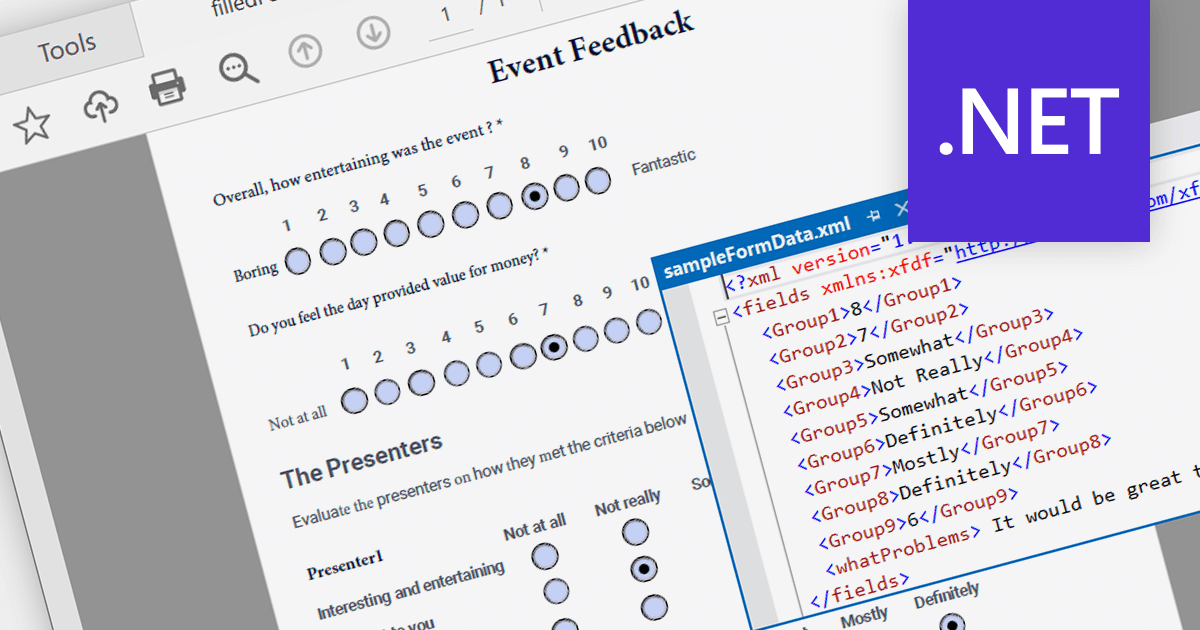
PDF data extraction is the process of programmatically extracting textual and visual information from PDF documents. It enables developers to parse files, extract text, images, and other elements, facilitating tasks like document indexing, and text mining.
Several .NET PDF components provide content extraction capabilities, including:
For an in-depth analysis of features and price, visit our comparison of .NET PDF components.
Tel: (888) 850 9911
Fax: +1 770 250 6199




