












Proveedor oficial
Como distribuidores oficiales y autorizados, le suministramos licencias legítimas directamente de más de 200 editores de software.
Ver todas nuestras marcas.
Continuar leyendo en inglés:
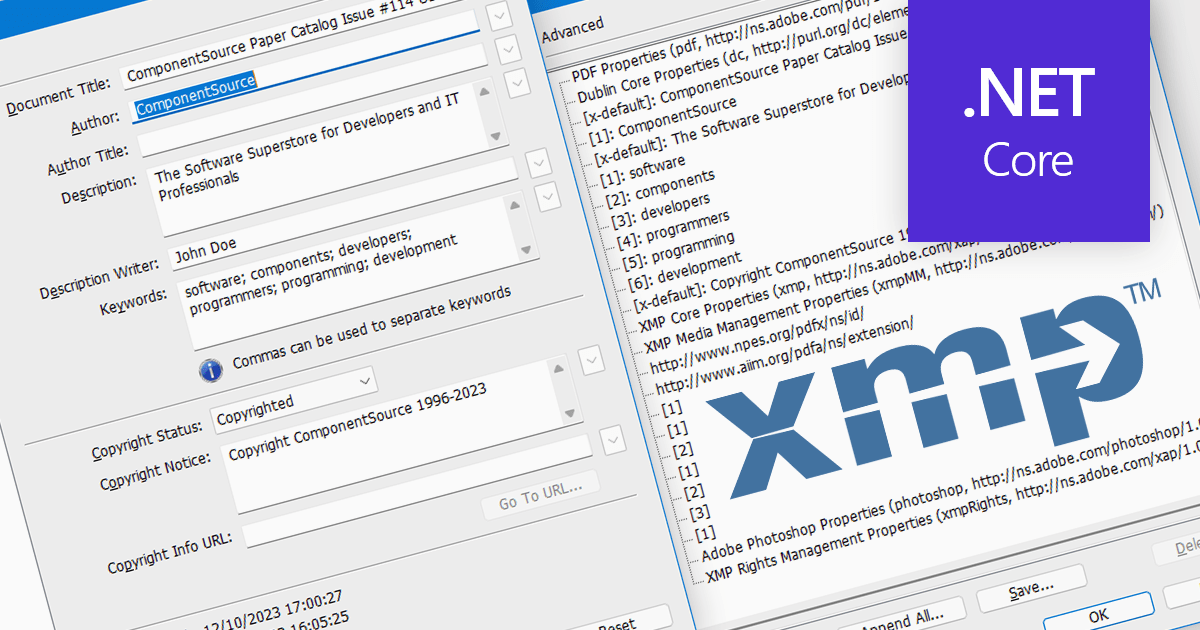
XMP, or Extensible Metadata Platform, acts like a digital label embedded within PDFs, carrying information beyond the document itself. It holds details like author names, creation dates, keywords, and even revision history. Programmatically extracting this XMP data unlocks a treasure trove of possibilities. Imagine automatically organizing PDFs based on author or keyword, extracting copyright information for legal purposes, or even tracing the evolution of a document through its XMP timestamps. This power makes XMP extraction invaluable for researchers, librarians, and anyone who wants to squeeze the most out of their PDF collection.
Several .NET Core PDF components support the extraction of XMP metadata including:
For an in-depth analysis of features and price, visit our .NET Core PDF Components comparison.
Tel: (888) 850 9911
Fax: +1 770 250 6199




