


Official Supplier
As official and authorized distributors, we supply you with legitimate licenses directly from 200+ software publishers.
See all our Brands.
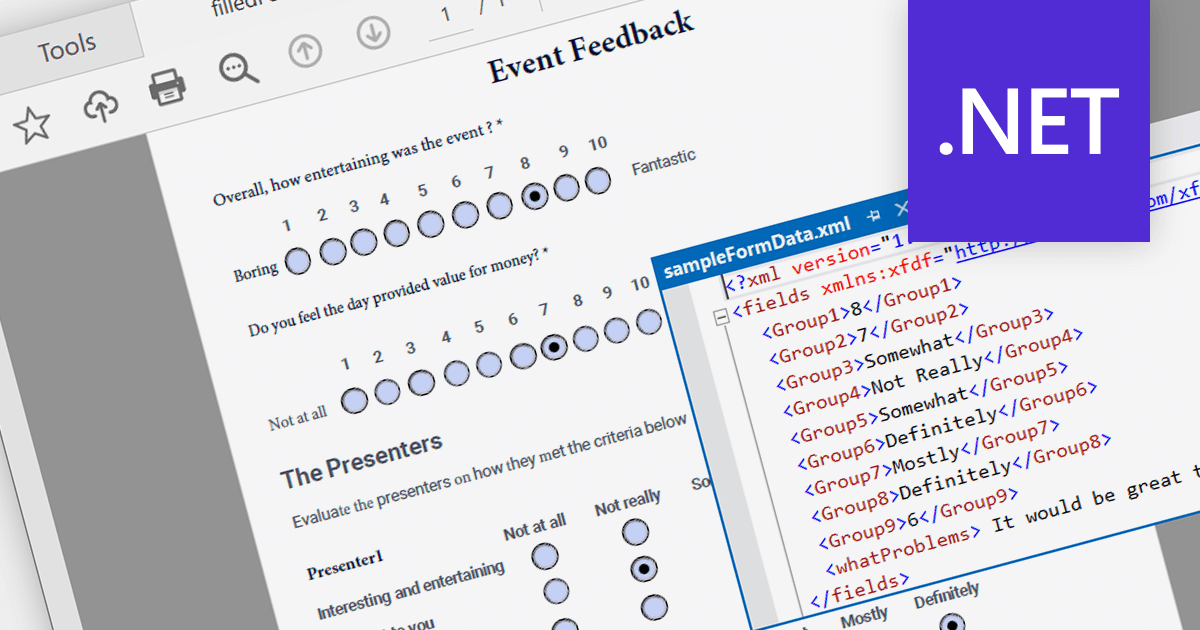
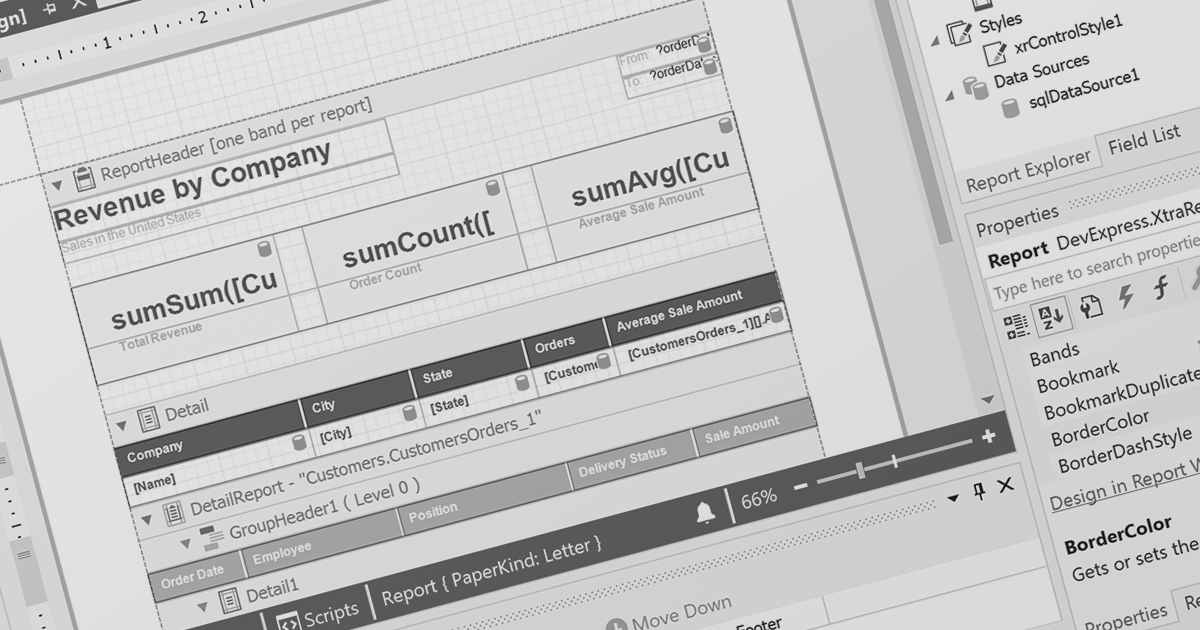
PDF data extraction is the process of programmatically extracting textual and visual information from PDF documents. It enables developers to parse files, extract text, images, and other elements, facilitating tasks like document indexing, and text mining.
Several .NET PDF components provide content extraction capabilities, including:
For an in-depth analysis of features and price, visit our comparison of .NET PDF components.










Tel: (888) 850 9911
Fax: +1 770 250 6199




