












공식 공급 업체
200 이상의 소프트웨어 개발처와 판매 계약을 맺은 공인 디스트리뷰터로서 합법적인 라이선스를 제공합니다.
모든 브랜드 보기.
영어로 계속 읽기:
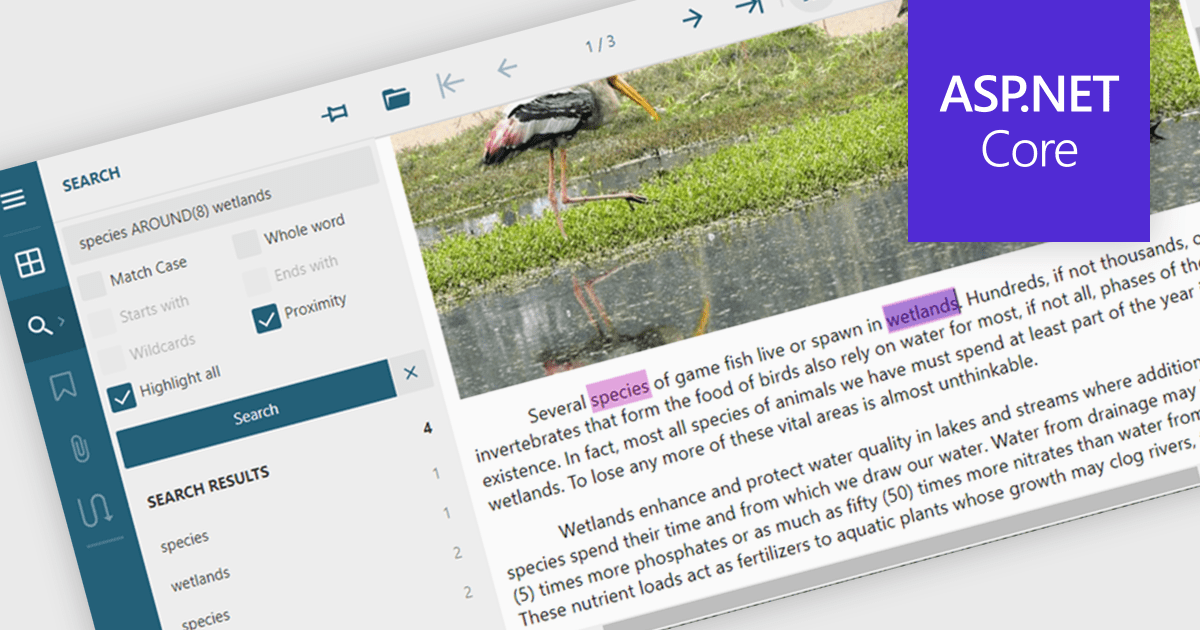
Text searching in a PDF component refers to the ability to programmatically locate and extract text within a PDF document based on specific search criteria. This functionality typically supports case sensitivity, whole word matching, and regular expressions, enabling precise querying across pages or document sections. For developers, it facilitates building features such as keyword highlighting, document indexing, content validation, and automated redaction workflows. By integrating text search, applications can efficiently interact with PDF content without manual review, saving time and improving data accessibility and accuracy across business and document automation systems.
Several ASP.NET Core PDF components allow you to search for text within a PDF file, including:
For an in-depth analysis of features and price, visit our comparison of ASP.NET Core PDF components.
전화 : 00798 14 800 6332
팩스 : +1 770 250 6199




